
Picture yourself at a bivouac just outside the city, a temporary refuge where you managed to get away for a little fresh air and a change of scene. Like all cities of its size, and like the relentlessness of rust, it never sleeps. And until this first night of freedom, it has kept you awake all too often too.
Your reprieve from urban vigilance wasn’t granted. You had to build it yourself. You started small, like this camp in the woods. Not even a tent, just enough warmth and a breathable mesh for shelter from the bugs.
A cricket chirps nearby. You sit up and see fireflies. Torchbugs, you call them, trained by your Skyrim escapism, the closest you could get to leaving your apartment.
Your phone is glowing through the sleeping bag, not nearly as bright as the bugs. You realize the cricket was the phone, so you pick it up, tap into the Cricket app you built to watch your servers, and you see there’s nothing to do. The bot had bounced a worker node, as permitted by the overnight rules. The node had gone yellow when it took a little long to come up, but it was green now. The incident report can wait for Monday.
Necessity and Invention
That scene is fiction. The full system doesn’t exist yet, but a technical spike is done (see Fig. 1 below), and the requirements for the full project are almost complete. A full working version of project bivy-mesh, comprising Cricket (a Go watcher) and Torchbug (an information radiator) will be my Boot.dev capstone. I’m giving myself a little more than 40 hours to write it, since I can’t bring myself to vibe code for course credit.
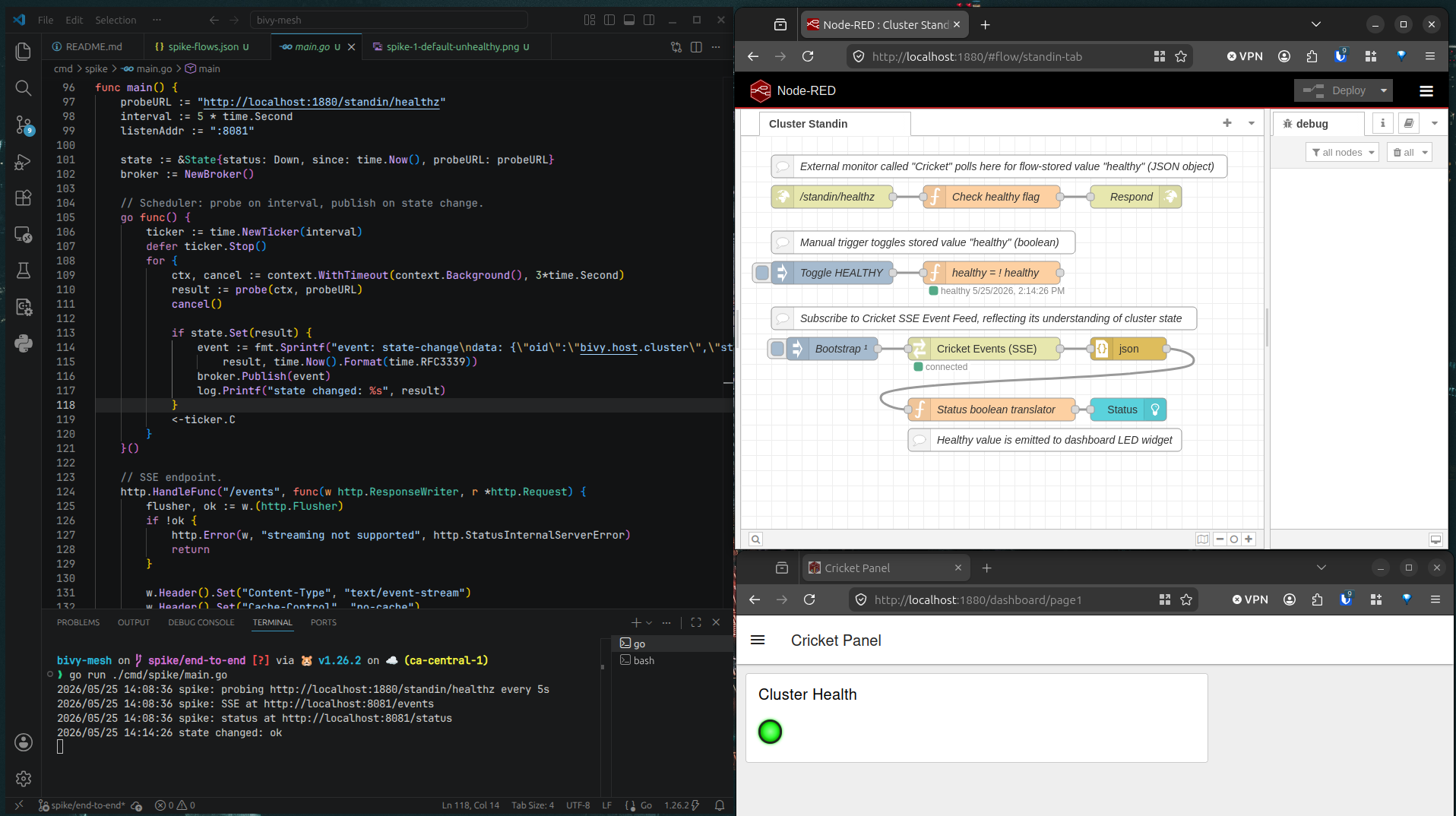
Fig. 1 – Cricket and Torchbug Spike
In a previous post I mentioned I had built a six-node K8s cluster as part of a reaction to a psychic snap. I wrote about cognitive dissonance, and about not being the server who “runs with soup” (a shlemiel), spilling it on the unsuspecting public (plural of shlimazel), not to mention your own teammates.
I have this silly idea that if you’re going to host something that real people use in the cloud, you have to expect it to get blown away. And if you should ever learn about your cloud wandering lonely as a … well, a cloud, and you get the news from some poor shlimazel who happened to be using your service, and you didn’t already know, you’re doing it wrong!
That’s why I’m building bivy-mesh, the subject of the slightly cringy vignette that started this post. Its purpose is to give me the means to throw all kinds of (unfortunately all too normal) trouble at my K8s cluster (think rushed releases, OS patching, unscheduled downtime, misconfiguration), and see what it takes to shrink the resulting downtime.
The reason for making a supervisory system of my own is the subject of a larger story.
Long Way Home
I started hosting things for other people around 2013 — a naval history association here
, an opera academy there
, a remote desktop sharing service reported here
, all originally on a rented server at OVH. I built the whole pipeline myself: Gitolite, Flask, Celery, blue-green deploys triggered by git push. It worked. I loved building it. And it was a Rube Goldberg machine that only its creator could maintain. No monitoring. No tested recovery. Some emergencies, but nothing I couldn’t handle.
Then in 2014 my family suffered a tragic loss. When the grief began to subside, the realization that my cousin’s opera academy, my Dad’s navy buddies, and my parents’ church would be in a serious bind if I was gone too. I set about eliminating single points of failure, and that could be hardware, software, or me. I learned how affordable it was to host static sites in AWS. Eventually all those workloads had been migrated to the cloud.
A few years later I found myself in the cloud too, fighting unexpected downtime for a cloud-hosted SaaS vendor, my employer. The customer was a small bank. I had spent the years leading up to that day dreading the moment. Given where I was in the company, and how few people knew what I knew, the very fact that I was nervous was evidence we were falling short.
We got through that event with only a few hours of downtime (yes, that’s far too long), and after the obligatory investigative exercises, we went back to not having enough people or money to do much in the way of prevention or drills (“it’s not in the contract”). I lasted another six months there.
Then life intervened, as it does for everyone, with more loss, and with duties that don’t wait for convenient timing. When I finally had space to write code again — a bootcamp, Go, HTTP servers, SQL — something snapped between one lesson and the next. The alarm bells from five years of ops wouldn’t stop ringing. Every line of code triggered the same kinds of question: Where’s the platform concern? What about the database ops for people self-hosting? Who gets paged at 3am when the schema won’t update? Isn’t this part better stored in a cache? How hard would it be to change it later?
I couldn’t just write the next handler. Not without answering those questions. So I built a six-node Kubernetes cluster, and started building the sort of automation I’ve so often been told isn’t worth funding. In this case, that means a configurable watchkeeper that never sleeps, that costs nothing to run, and that lets me measure the effects of software architecture on site reliability.
The notion of “long way home” is an antidote to economic drivers that kept me focused on billable work at the expense of doing the right thing. Today, nobody has to approve any of my time, and so you can expect me to take excursions into technical areas I would have been required to set aside when I was on the clock.
Expect more on this subject.
Banner photo by Renaud Confavreux on Unsplash